A dip in the data pool
In the distant past, individual insurers had relatively modest business volumes and the industry needed to pool its data to get an overall data set of sufficient credibility. In the U.K., the mechanism for pooling mortality data is the CMI. An earlier blog mentioned some challenges surrounding the changing volumes of data in the CMI assured lives data set. Figure 1 is an animation showing the development of the CMI exposed-to-risk figures over time.
Click the chart to restart the animation.
Figure 1. Male assured lives exposed to risk at each age since 1947
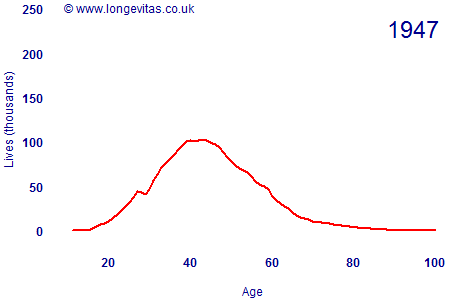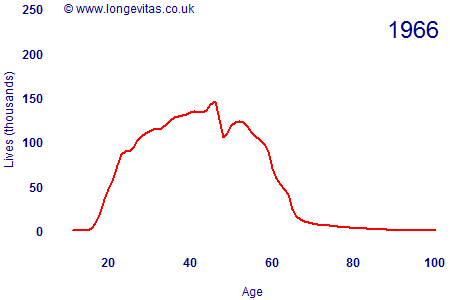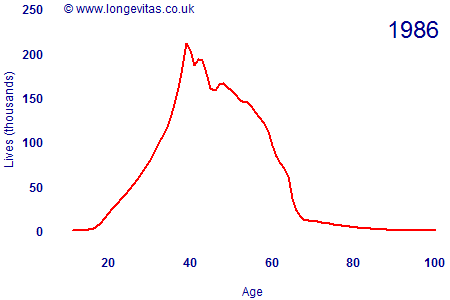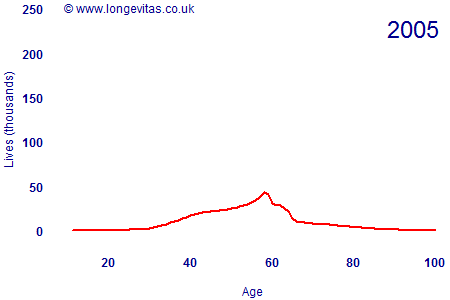
Volumes for this particular data set have fallen sharply in recent years, seemingly quite a bit faster than could be explained by deaths and maturities alone. It is likely that many holders of endowment policies have surrendered them for cash, for example, but it is also possible that some offices are no longer submitting data to the CMI.
In the past few years, dedicated own-company analysis has become much more popular. In contrast to the past, individual life companies nowadays often have data sets large enough to do bespoke analysis without needing to pool their data with others to get credible data volumes. The advent of survival models gives a superior ability to model multi-year data compared to models for qx. This means that modern actuaries can do in-house analysis with many more rating factors than could be done with historic pooled data.
Add new comment