Rewriting the rulebook
It is an unfortunate fact of life that through time every portfolio will acquire data artefacts that make risk analysis trickier. Policyholder duplication is one example of this and archival of claims breaking the time-series is another. Data errors introduced by servicing are perhaps the most commonplace of all, and this posting describes how validation rules can protect the modelling stage from such errors.
The first class of issue is the generic data corruption, termed generic because these problems occur with the same characteristics in more or less every portfolio you work with. Generic validation rules are critical here, screening out such problems before modelling commences. These issues include invalid or inconsistent birth-, commencement- or end-dates, corrupt gender codes, missing or invalid benefit amounts along with a variety of other elephant-traps.
The second class of issue is the portfolio-specific corruption, and these often masquerade as valid data. Such issues occur most commonly where a servicing team has created conventions using special marker values inside standard fields (like postcode, surname, or birthdate) to record data conditions the administration system does not capture adequately any other way.
You can trap portfolio-specific issues by looking at common occurrences. A portfolio with 20,000 members probably shouldn't contain 2000 people with the same birthdate — 1900-01-01 is a popular example. And finding 150 members all with a surname of "TESTDATA" seems to be telling us something as well! Attribute misuse like this usually precludes modelling with the affected data.
Where common occurrences like these suggest portfolio-specific screening rules, then it would be ideal to add these to an automatic rule-set for use whenever related portfolios are handled. After all, many models are revisited at least annually, and others even more frequently than that. To assist with this aspect of validation, Longevitas now allows you to create rulesets for the validation of specific datafiles. Here is a small ruleset in CSV format that would catch the issues we discussed in the previous paragraph:
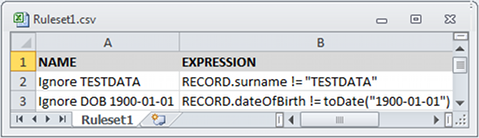
In Longevitas, rules are Java-like Boolean expressions that return a True or False. When applied to a given record, a True result allows the data to remain usable, but False causes it to be rejected and excluded from modelling. Such rulesets allow you to automate the validation and removal of portfolio-specific data problems. By always operating after comprehensive generic screening rules, the rules you create only have to worry about very specific conditions. This makes them much simpler to write.
No discussion of validation rules is complete without considering the validation of rules. To that end Longevitas checks each ruleset against randomly generated data when it is first introduced to the system and portfolio data will only be tested against rules that prove valid. In addition, you can easily inspect all portfolio data rejected by any rule to make sure everything is behaving as you expect. After all, if this area teaches us anything, it's that you can't be too careful!
Add new comment