Special assignment
We talked previously about the use of user-defined validation rules to clean up specific data artefacts you sometimes find in portfolio data. One question came up recently about modelling bespoke benefit bands, and this can also benefit from user-defined rules.
In our modelling system we automatically calculate a user-selected number of benefit bands, each containing a broadly equal number of lives. The model optimiser can be used to cluster these bands, giving you the best-fitting break points for your experience data. A drawback is that the optimised break-points might not correspond to any pre-established business convention. So, what do you do if you want a constant banding for use with all files?
One possible answer is to upload a file with your banding in place as a user-code field. However, if the portfolio requires deduplication, then the merging process will in most cases sum the benefits across all duplicates, which can invalidate the pre-loaded banding.
The solution is to employ a bespoke assignment rule, which might look something like this:
if (RECORD.annualPension<=5000) RECORD.setCode("Income", "Low");
else if (RECORD.annualPension<20000) RECORD.setCode("Income", "Middle");
else RECORD.setCode("Income","High") ; ASSIGNMENT()
The ASSIGNMENT() call at the end of the rule tells the system that this logic must fire not only for all uploaded data, but also for any data created as a result of merging duplicate portfolio members. Whilst the thresholds shown will change with different classes of business — since what represents high income in an executive scheme is quite different from the top-end in a portfolio of manual workers — the principle remains the same. By encoding the banding in a rule that fires after any system deduplication and merging is performed, we can ensure correct handling irrespective of the number of policies any individual might have.
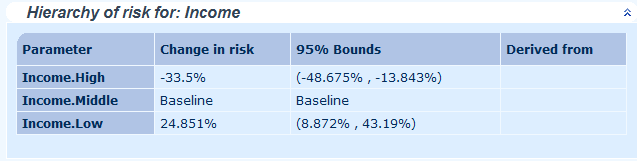
Data created via assignment rules is functionally the same as any other data you upload. It will be available in extracts and audit reports, and can be included in models to check importance as a rating factor:
Add new comment